Methodology
Perception of Extrinsic Features

Perception of Intrinsic Features
VLM Prompt Detection

LLM Navigational Scene Understanding

Scene Understanding Cost Map
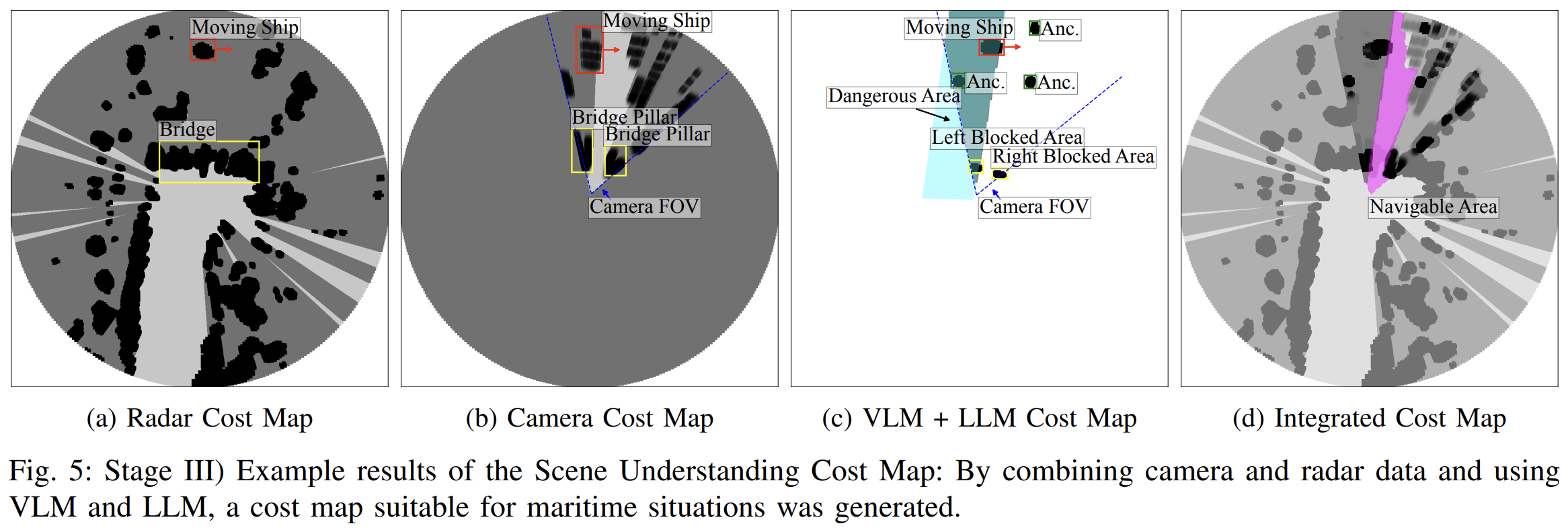
In this study, we introduce an innovative algorithm for enhanced navigational scene understanding in complex canal environments by utilizing large language models (LLM) and visual language models (VLM) to achieve autonomous maritime situational awareness. The proposed algorithm interprets the meanings of various features and marks on detected objects in maritime contexts. By combining this information with radar and camera data, the algorithm generates cost maps for safe navigation. This approach offers two key benefits: (1) the ability to identify navigable areas considering obstacles, maritime marks, rules, and ship intentions, and (2) decision-making support based on reasoning, bridging the information gap between human operators and perception results. The performance of the proposed approach is demonstrated using a real-world dataset.
@inproceedings{shin2024llmship,
title={Enhancing Navigational Scene Understanding using Integrated Language Models in Maritime Environments},
author={Shin, Yeongha and Kim, Jinwhan},
booktitle={},
year={2025},
organization={},
note={Robotics Program, Korea Advanced Institute of Science and Technology (KAIST)}
}